5.5 Algorithm - FedAdam
Implement Federated Learning with the Adaptive optimization method Adam (FedAdam) algorithm[1].

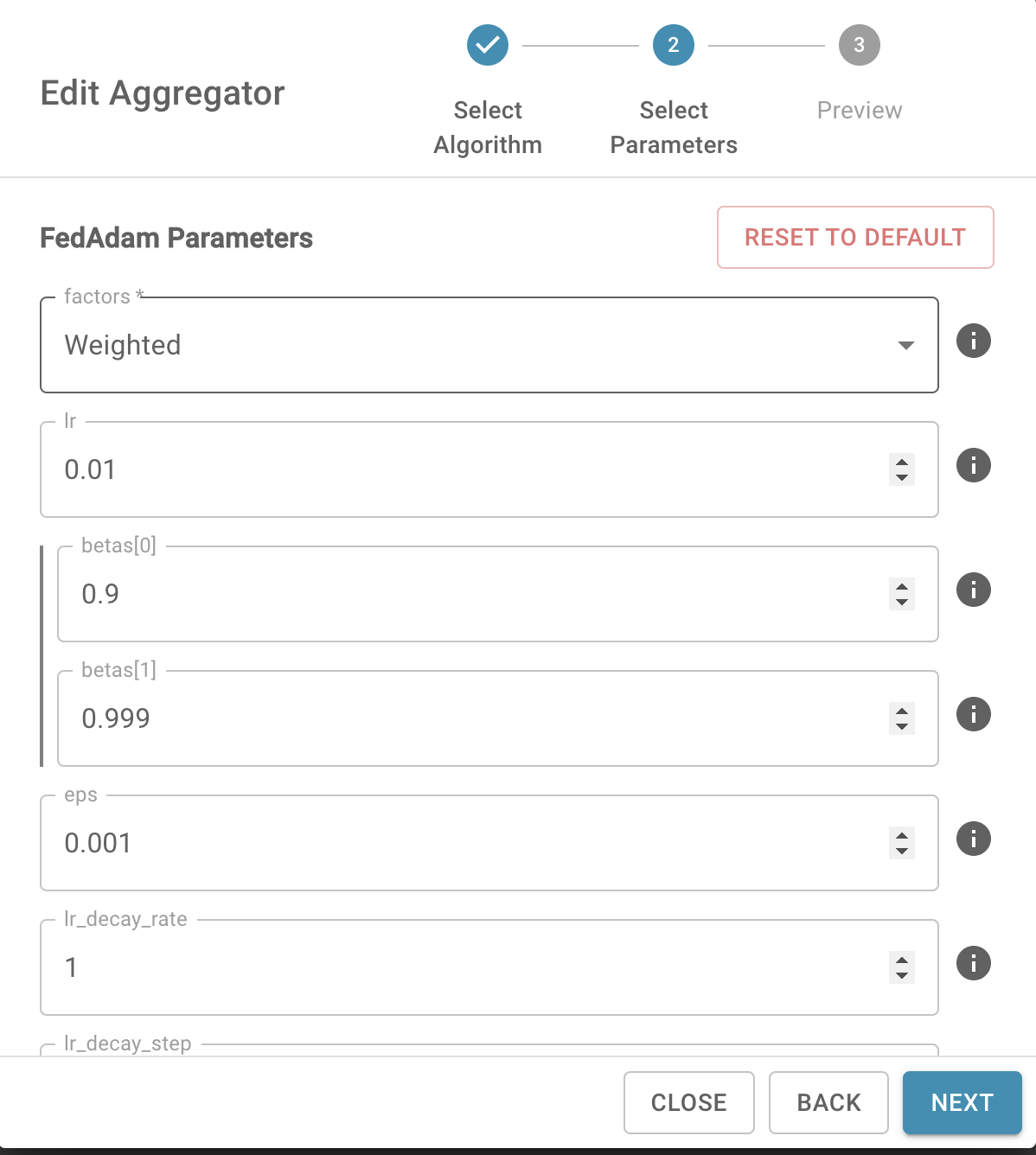
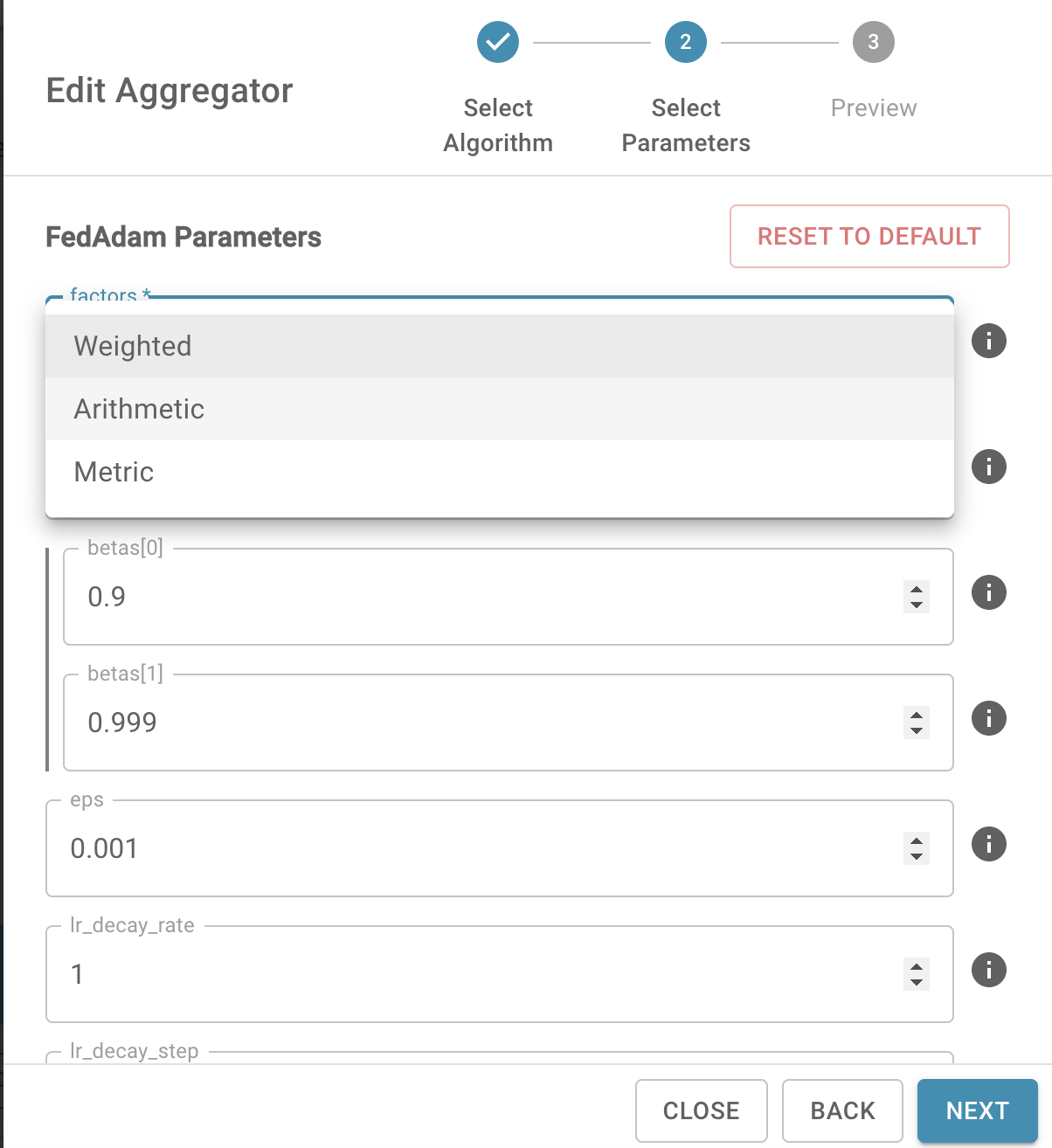
Parameters
- factors (str, optional) - aggregation weight mode (default: "weighted")
- "weighted": weighted average based on the size of local datasets
- "arithmetic": arithmetic average
- "self-defined": weighted average according to user-defined weights
- lr (float, optional) - learning rate (default: 0.01)
- betas (Tuple[float, float], optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
- eps (float, optional) - term added to the denominator to improve numerical stability (default: 1e-3)
- lr_decay_rate (float, optional) - learning rate decay factor (default: 1)
- lr_decay_step (int, optional) - period of learning rate decay (default: 100)
- bias_correction (bool, optional) - bias correction (default: False)
Reference
The user interface of FedAdam algorithm: